

棋譜DB2はプロ棋士、コンピューターの棋譜が鑑賞でき、ユーザー同士でコミュニケーションできる新しい棋譜データベースサービスです。floodgateの最新棋譜も鑑賞できるしサインインすればお気に入りの棋譜を登録したり棋譜にコメントしたり新着棋譜をメールで知らせてくれる機能もあり至れり尽くせりです。サイトの作りも洗練されていてちょっと棋譜を確認したいときなどは検索などから目的の棋譜を探し出すこともできます。さらに棋譜をcsa,kif,ki2各形式でダウンロードすることもできます。棋譜をダウンロードして収集することで柿木将棋を使った局面検索、棋譜の一部分を抽出加工しオリジナル定跡ファイルの作成、バッチ処理をかけてノンストップの棋譜再生など様々な活用法、利点が生まれます。

今回は棋譜DB2から手作業でなく一括で棋譜を取得する方法について工夫してみたいと思います。それにはWebスクレイピングという手法を使います。スクレイピング手法は色々ありプログラミングをされる方はPerlやPythonなどの言語をよく使われるようです。私はプログラミングできませんのでGoogle Chrome拡張機能のWeb Scraperを使った方法をご紹介します。このWeb Scraperは主にテキスト、表、リンクなどの情報を抽出できます。
Web Scraperは高機能ですが日本語の解説が少なく記事をまとめるのに苦労しました。用途は棋譜取得以外にも変動するWebサイトからの定期的な情報収集、商品販売サイトから価格などの情報を取得して分析、または業務効率改善などに活用できそうです。ゆえにニーズはあるものと思います。
まずはインストール
まず最初にすることはWeb Scraperをインストールすることです。ChromeウェブストアのWeb Scraperにアクセス。Chromeに追加で機能を有効にしてください。

するとGoogle Chromeの右上のツールバーの所にグレーの蜘蛛の巣みたいなマークが現れます。そしてこのマークをまず右クリックしてください。

すると上の図のようにポップアップメニューが現れます。「Web Scraper」はChromeのWebストアに飛びます。「オプション」をクリックすると下の画面になりますがこのままの設定にしておきます。

ポップアップメニューの他のメニューもそのままにしておきます。グレーの蜘蛛の巣マークを今度は左クリックすると以下の表示画面になります。
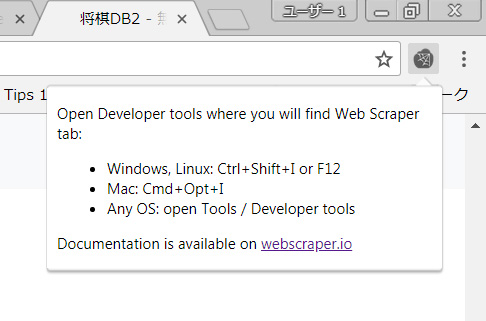
Web ScraperのタブはデベロッパーツールにあるからWindows、LinuxはCtrl + Shift + IまたはF12, MacはCmd + Opt + Iで開くように言われます。実はこのショートカットを使わなくても右クリック→検証で開きます。デベロッパーツールはWebサイト構築する際とかに便利でスマホやタブレットでどう表示されるかも確認できます。デベロッパーツールを開くと下の図のようにWeb Scraperのタブが追加されています。
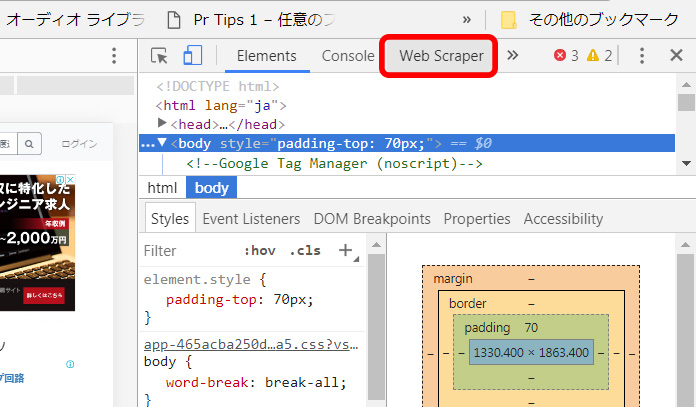
デベロッパーツールが右に表示されてあるとWeb Scraperのタブをクリックすると下の図のようにデベロッパーツールをブラウザの下に移動させよと言われるのでその通りにします。
閉じるボタンの横の点三つボタンをクリック→Dock to bottomを選択
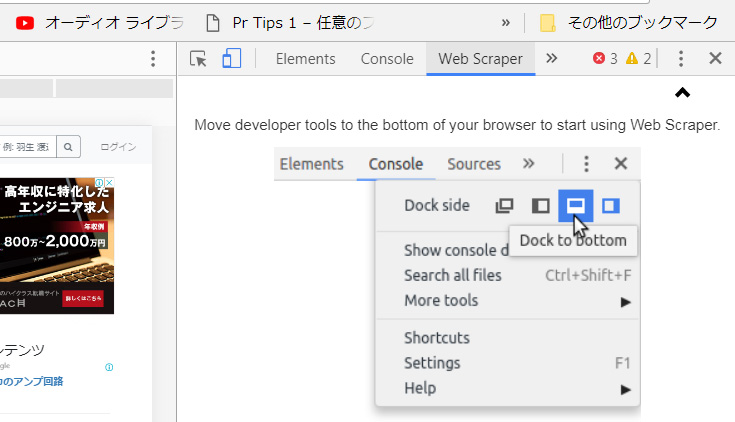
下の図はデベロッパーツールを下に移動させたところ。
棋譜DB2を例にして使っていく
それではいよいよ実際に使ってみます。棋譜DB2のトップページを表示させておきます。
「Create new sitemap」→「Create Sitemap」と選択します。
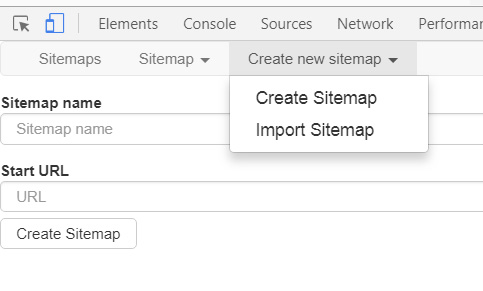
すると以下のような画面が現れます。
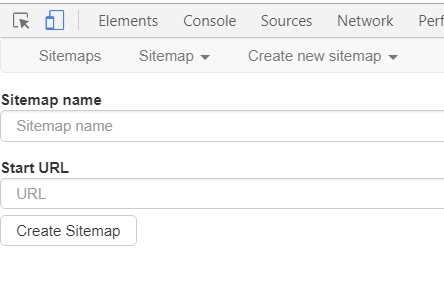
「Site map name」に任意の文字列を入力しますが、「将棋DB2」などと日本語を使ってしまうと下の図のようにエラーになります。
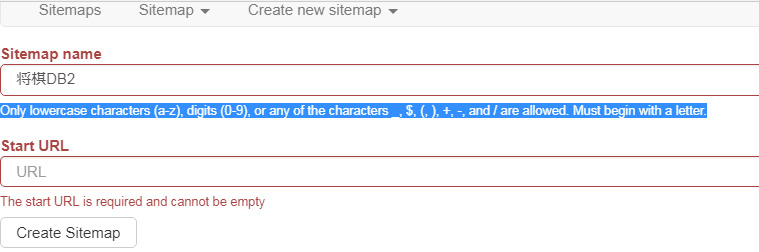
「小文字(a〜z)、数字(0〜9)、または_、$、(、)、+、 – 、/のいずれかの文字のみが許可されます。文字で始まる必要があります。」(翻訳)
だそうです。shogidb2で通りました。
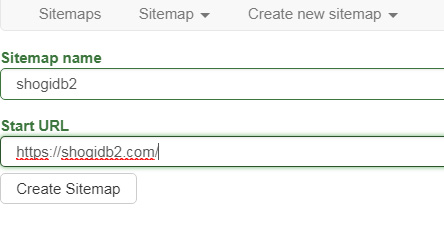
「Start URL」には取得したいサイトのURLを入力します。
そして「Create Sitemap」をクリック。すると以下の画面に移行します。
青字で_rootという文字が見えます。
これはルートディレクトリの意味でさっき貼り付けたURLになります。
ルートディレクトリはコンピューター用語でWEBでは基点などの意味です。
ここでは棋譜DB2サイトのトップページになります。その前に・・・。
サイトの構造の把握
まずはじめにしなければならないことはサイトの構造を把握しておくことです。棋譜DB2サイトの場合、トップページに最新の棋譜、新着の棋譜、floodgateなどのリンクが並んでいます。「最新の棋譜」のリンクに飛ぶと日付が新しい棋譜から順に並んでいます。それに対して「新着の棋譜」のリンクに飛ぶと投稿された順に並んでいます。この2つのリンクから棋譜を抽出した場合、重複する棋譜が出てきますからどちらか一方のリンクから棋譜を抽出していきます。今回の例では「最新の棋譜」にします。
URLのパスについても確認しておいたほうがいいと思われます。
今回の場合トップページは https://shogidb2.com
最新の棋譜ページは https://shogidb2.com/latest
新着の棋譜ページは https://shogidb2.com/newrecords
floodgateページは https://shogidb2.com/floodgate
さらに最新の棋譜、新着の棋譜、floodgateページには上部と下部にページネーションと呼ばれるナビゲーションが付いています。そこの数字をクリックしてURLを確認してみるとそれぞれ以下のような形式になっていることが確認できます。
https://shogidb2.com/floodgate/page/1
https://shogidb2.com/floodgate/page/2
https://shogidb2.com/floodgate/page/3
構造が確認できたらいよいよルールを作っていきます。やりたいことは最新の棋譜(latest)を取得することだとします。まず青いボタンの「Add new selector」をクリック。すると下の画面になります。このままだと狭くて入力しずらいのでサイトとデベロッパーツールの境界線をマウスで選択してデベロッパーツールを広げてください。
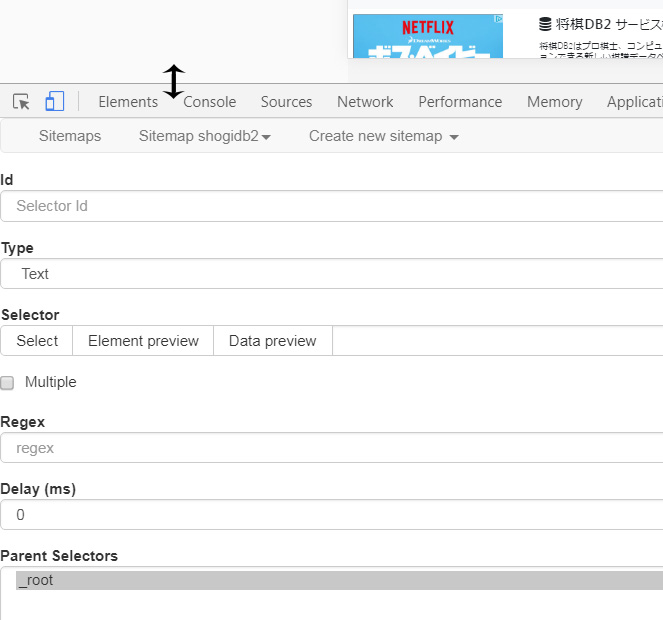
ここからサイトマップのルールを作っていきます。まずidに任意の名前を半角英数でいれます。ここではサイト構造に合わせて分かりやすく最新の棋譜のURLパス「latest」と入れます。Typeのプルダウンはlinkを選んでおきます(他の項目については後述します)。Selectorには3つのタブ(Select/Element preview/Data preview)が見受けられます。まずSelectタブをクリック。するとポッキーのような棒が現れます。

これが現れたのを確認してからサイトのリンクをクリックします。
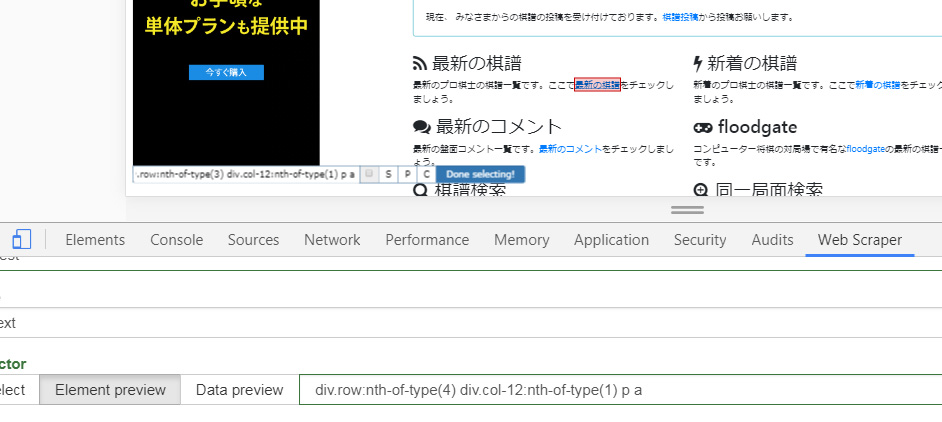
すると上図のように指定したリンクの部分が赤く色づきます。「ポッキーのような棒」が出ていない時にリンクをクリックしますと普通のリンクとして機能しますので注意してください。それから「ポッキーのような棒」に表示されるリンクのhtml要素を確認したら青色部分のDone Selecting!(選択完了)をクリックします。そして青色ボタンのSave Selector(設定保存)をクリック(下図)。
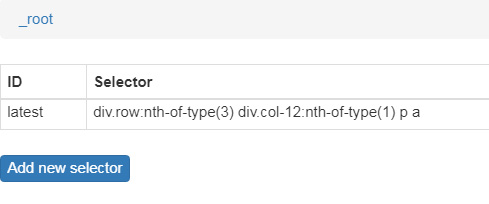
すると下図のようにルールが適用されました。
Element previewで選択を再確認することが出来ます。

そしてData previewをクリックで以下のようになります。

ここまで表示されたら成功です。「最新の棋譜」という文字列、そして「https://shogidb2.com/latest」というURLが取得されています。基本的にはこの作業を繰り返していくことになります。簡易的な使い方をするのであればここから文字やURLをコピペして活用されてもいいでしょう。とっつきにくいインターフェイスだし英語ですが使い続けていくと慣れます。
さらに深く
それでは次に階層を深くたどって抽出するためのルールを作っていきます。それにはまず下の図の赤枠で囲った部分をどこでもいいからクリックします。

すると下図のように_rootの文字の右にlatestという文字が追加されました。
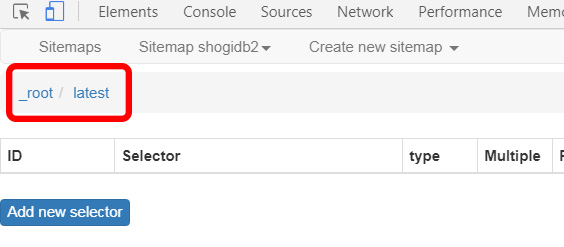
ここからはlatest(最新の棋譜)からのルールを作っていくことになります。サイトのほうも最新の棋譜に移動しましょう。青色ボタンのAdd new selectorをクリック、idにtitleとでも入れておきます。TypeもLinkでOK。
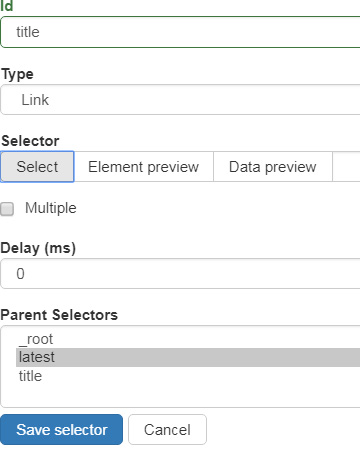
SelectorのSelectタブをクリックして「ポッキーのような棒」が現れたのを確認したら下の図のようにタイトルあたりをクリック。先ほどLinkを選択したのでリンク全体が選択されていますね。このままで問題ありませんがHTML要素を個別に選択することもできます。
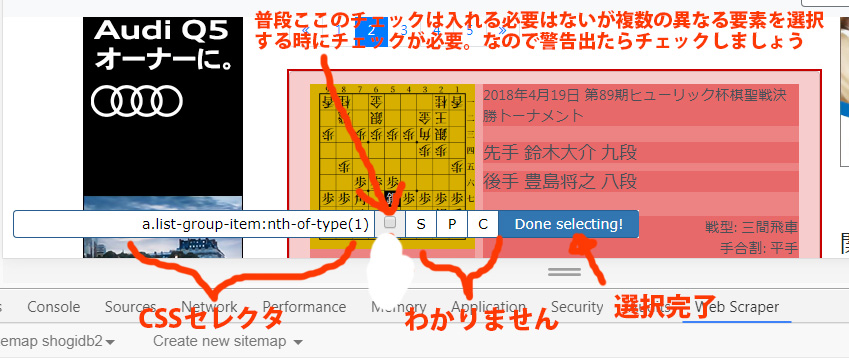
Done Slecting!が終わったらElement previewタブでエレメント(赤色部分)を確認できます。
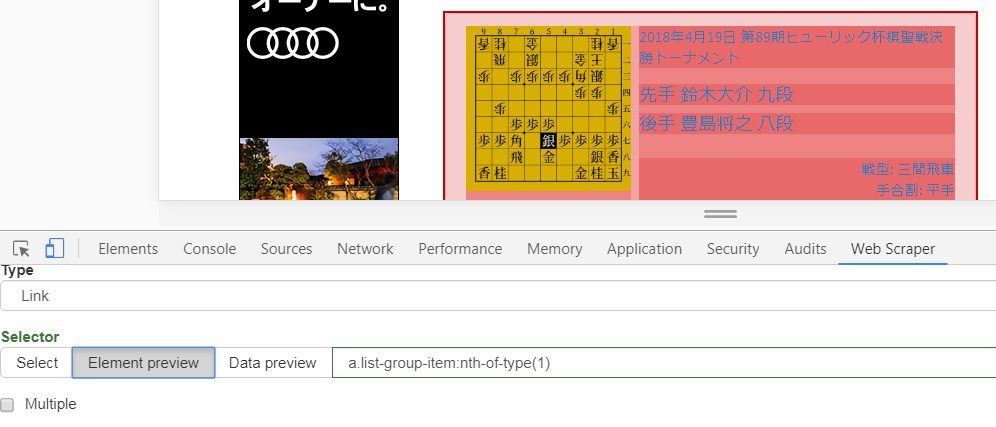
さらにData previewタブで取得するデータを確認できます。

しかしこの方法だとページ内の1つの要素(この場合は鈴木九段と豊島八段の棋譜)しか取得できません。もちろんページ全ての棋譜を取得したいわけです。なのでタブの下のMultiple(複数)にチェックを入れてSelectタブでリンクを選択していきます。

すると複数リンク取得できます。この時に間違えて選択されたらElement previewをクリックすればリセットできます。選択されるときに緑になったらダイアログボックスにチェックを入れて選択しなおせばOK.ポンポンと複数の棋譜を選択していきます。途中から自動で一括選択されると思います。

Multipleにチェックを入れなくても画面上では赤く複数選択されてるように見えますが実際はされてないので注意が必要です。選択終わったらDone Slecting!
そして青色ボタンのSave Selectorで設定を保存します。

Element preview、Data previewなどで確認してみましょう。
ここではさらに下の階層を抽出するルールを作っていきますが結果的にはこれからの手順は失敗しました。
なので実際の作業はしないでもらっても構いません。いきなりスクレイピングしてもらって構いません。
失敗した手順

上図の赤枠をクリックします。そして青色ボタンのAdd new selector。そして下図のように入力します。
やりたいことは棋譜の書き出しからki2で保存することだとします。なのでidにki2、TypeにはPopup Link(ポップアップウィンドウに棋譜が表示されるようになっているから)、そしてki2のリンクを選択すればa#ki2-exportと自動的に入ります。
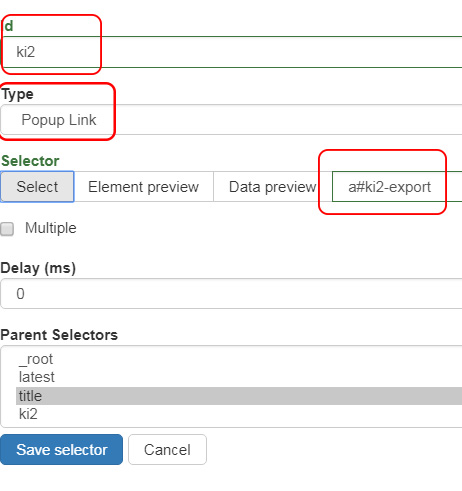
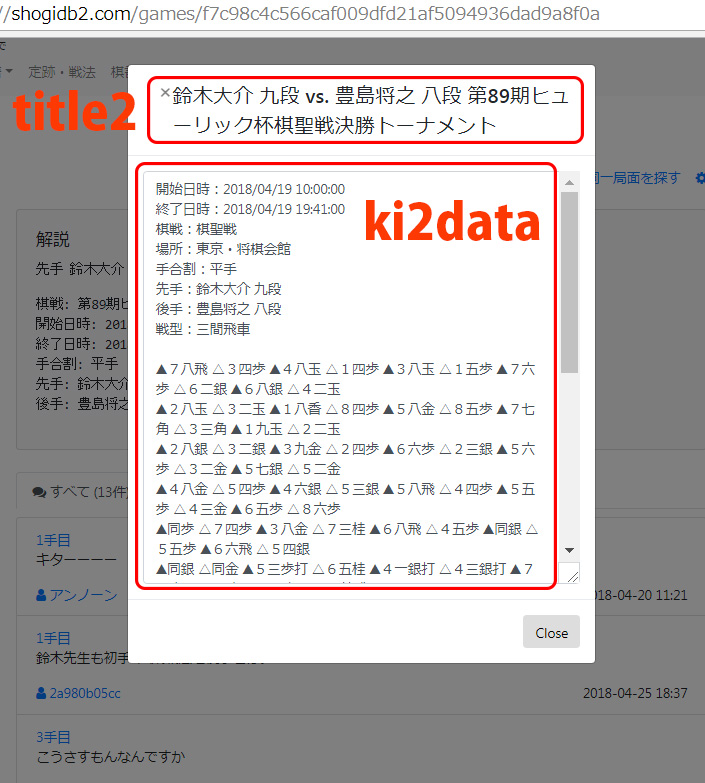
で、さらに下にタイトルと棋譜部分を抽出するセレクタを作っていきます。下の図のようにポップアップウィンドウからタイトル部分をtitle2として抜き出し、棋譜が表示されている部分をki2dataとして抜き出そうとしてみます。
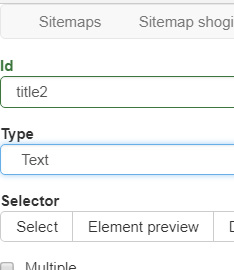
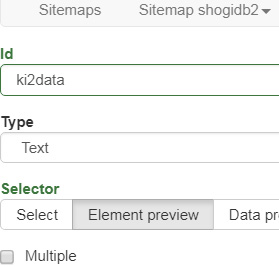
設定はそれぞれ以下に。テキストだけ抽出できればいいのでTypeをTextにしてあります。

そしてSitemap shogidb2→Scrape→Start scrapingで別ウィンドウが開いてスクレイピング開始します。しかし下図のように棋譜部分は取得されません。クリックイベントを検知しているような感じだと思いますが、このツールの限界かも知れません。プログラム書ける人なら対処できるのかも知れません。残念ながらタイトルと棋譜をいっぺんに取得する方法はあきらめます。タイトルとリンクだけを取得することに満足します。
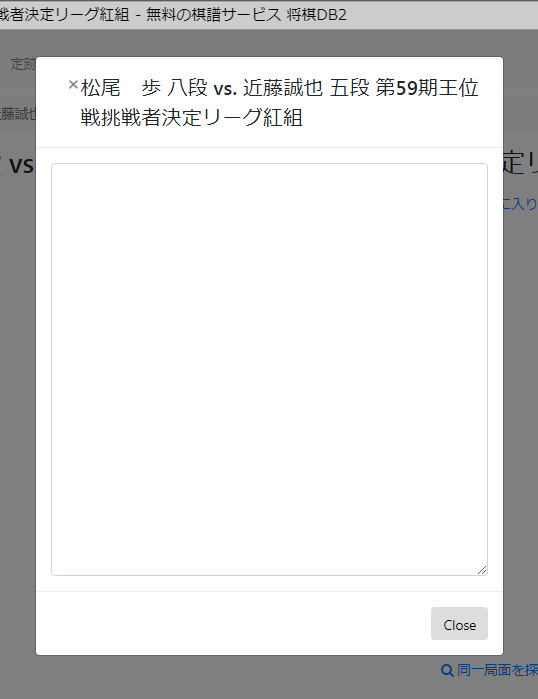
idをki2とする前の手順に戻ります。またはki2以降を削除します。
いよいよスクレイピング!
スクレイピングする前に出来上がったルールを確認してみます。まず「Sitemaps/Sitemap shogidb2/Create Sitemap」と並んでいるタブの一番左、Sitemaps(複数形になっている)をクリックします。
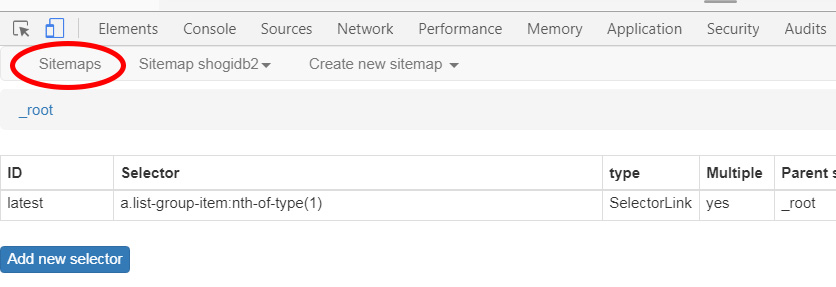
すると今までに作ったサイト一覧が表示されます。ここでサイトを選ぶとタブのSitemap shogidb2タブのSitemap以降の文字列が切り替わります。ではSitemap shogidb2タブをクリックしてみます。
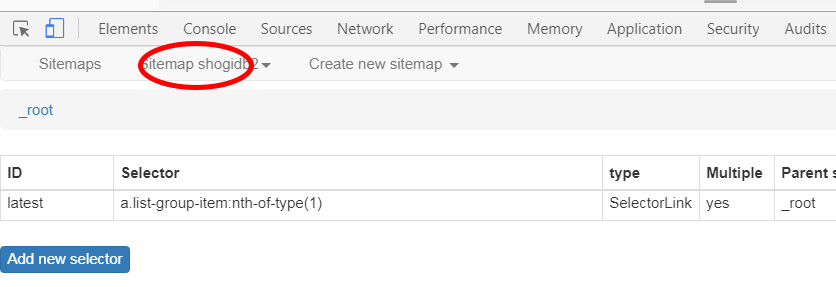
するとプルダウンメニューが出てきます。
- Selectors セレクタの編集ができる。よく使う。
- Selector graph サイトのツリー構造が視覚的に確認できる
- Edit metadata 最初に作った名前とURLです
- Scrape 実際にスクレイピングする時にクリックする
- Browse その結果
- Export Sitemap 作成したサイトマップを出力して保存する時に使います
- Export data as CSV 作成したサイトマップをCSV形式で出力します
まずSelectorsはデフォルト画面というかここからElement previewで要素を確認したりData previewで出力結果を確認したりEditで再編集したり。このData previewで個別の項目の出力が出来ます。
次にSelector graphの使い方、セレクタが視覚化されて理解を助けます。_rootの青丸をクリックするとカタツムリの触手のように分岐が伸びていきます。

次にScrapeをクリック。するとRequest interval (ms)とPage load delay (ms)の2つの項目が見受けられます。この(ms)はミリ秒、1000分の1秒の単位です。デフォルトでは2000、つまり2秒になっていますがこれがサイトに負荷をかけない設定のようですのでここはそのままにしておきます。
準備は出来てます。スクレイピングしましょう!
Start scrapingをクリックすると別ウィンドウが開いてスクレイピング開始します。「No data scraped yet. 」と表示されたらrefleshをクリックします。簡単に使うならここで表示されたテキストデータやリンクなどコピペして活用してもいいでしょう。先ほどのタブのExport Sitemapで設定を保存できます。
そしてImport sitemapで読み込めます。
Export data as CSVをクリックするとCSV形式(エクセルなどで読み込める形式)で保存出来ます。ただCSVファイルをエクセルで読み込むときに日本語が文字化けするかも知れません。下の図では文字化けしています。

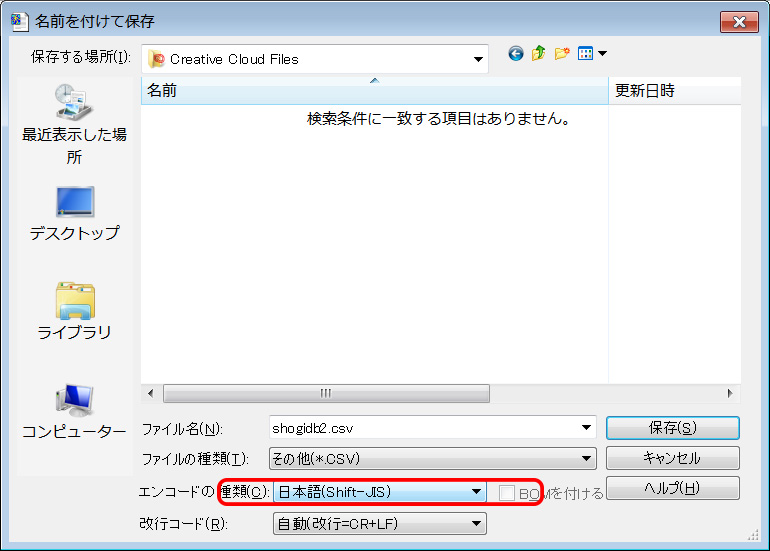
※以下の方法はテキストエディタの秀丸を使う方法です。秀丸は大変便利なソフトで文字編集に威力を発揮します。秀丸マクロを使えば例えば文字数をカウントしてくれたり、日付を自動入力といったこともできます。そしてヘルプが充実しています。柿木将棋もそうですがヘルプが充実しているソフトは信頼できると思います。秀丸は私がパソコンをセットアップしたら真っ先にインストールするソフトです。シェアウェアですがそれだけの価値はあると思います。エクセルに慣れていて関数などを理解されているような方はエクセルで整形したほうが早いかも知れません。あるいは秀丸以外のテキストエディタを使っても似たような事ができると思います。
文字化けした場合はCSVファイルをいったんテキストエディタで開きエンコードの種類をUTF-8からShift-JISに変更して保存しなおしてからエクセルで開くと文字化けが解消されます。下の図はテキストエディタの秀丸からShift-JISで保存しようとしているところ。
そして再度エクセルで開きます。タイトルとURLが取得できました。順不同だし不要な列もあるので整形して見やすくしてもいいでしょう。最後のほうで並び替える方法についても紹介しています。

他の設定を確認
ここではLink、Popup Link、Textと3つのタイプしか使いませんでしたが、他のタイプも確認しておけば応用をきかせられそうです。Typeのプルダウンからlink以外の項目の詳細を確認していきます。基本的に取得したいタイプを選びます。表示されている項目を上から順に…。
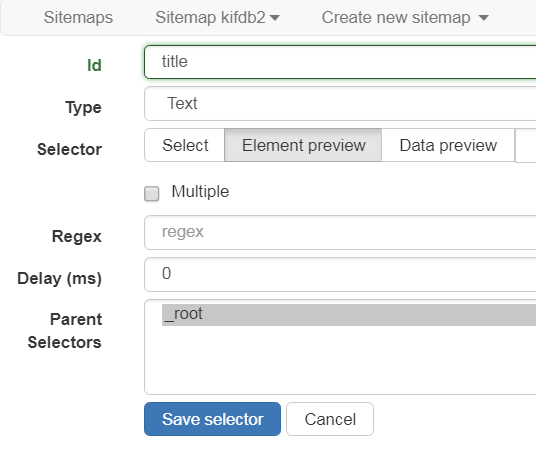
- Text テキストのみを抽出する、HTMLは削除される
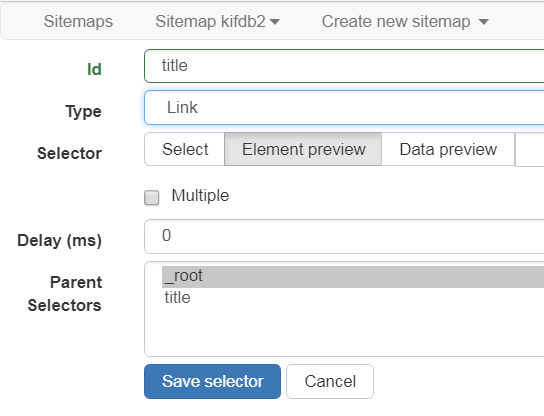
- Link ハイパーリンク
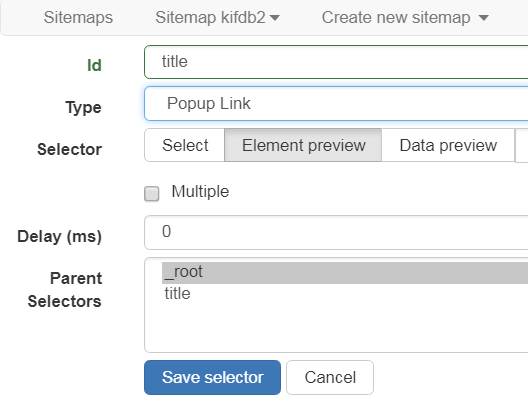
- Popup Link ポップアップリンク
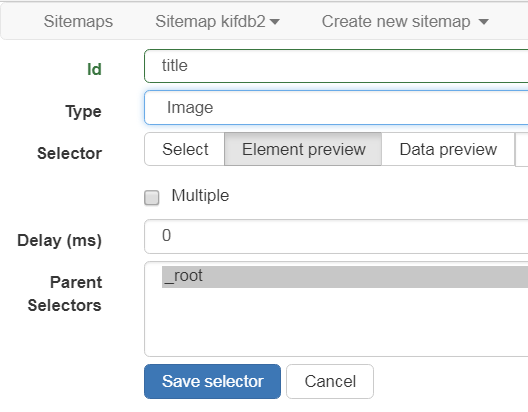
- Image 画像のURLを抽出する、画像のダウンロードはできない
- Table テーブル
- Element attribute 要素属性を抽出
- HTML HTMLとテキストを抽出できます
- Element 要素
- Element scroll down スクロール要素
- Element click クリック要素、ページネーション抽出など
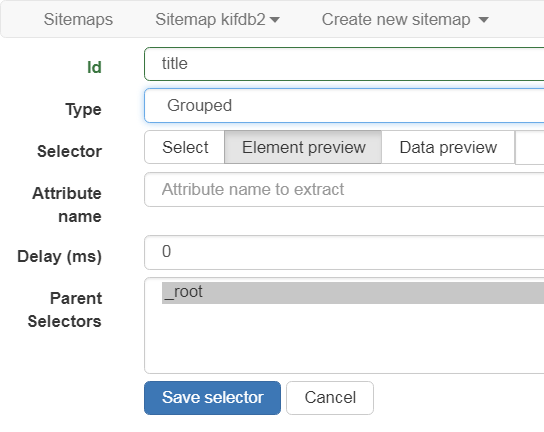
- Grouped グループ化された
Text
Link
Popup Link
Image
Table

Element attribute
HTML
Element
Element scroll down
Element click
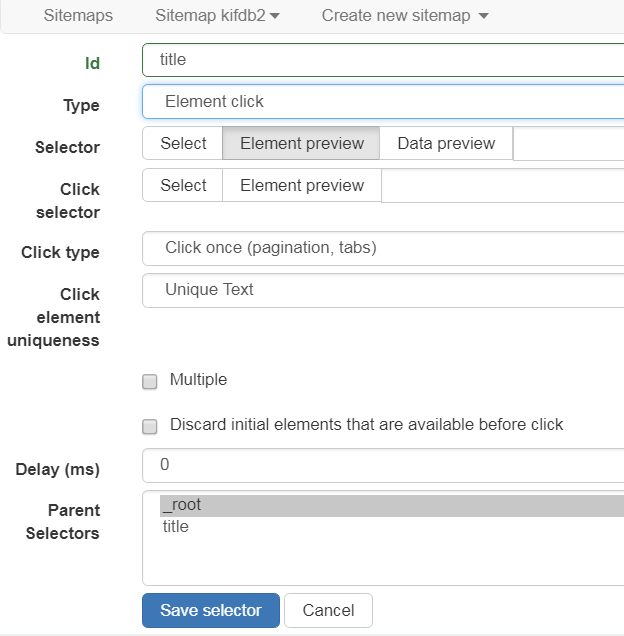
Grouped
このうち Link, Popup, Link, Element, Element scroll down は項目が同じ。
Text, HTML の項目も同じ。他は微妙に違います。
ページネーションを移動して抽出する方法
この棋譜DB2サイトは前述したようにページネーションが使われています。こういったサイトから情報を収集する際に便利な機能があります。以下のようなURL構造になっていることを利用します。
https://shogidb2.com/newrecords/page/1
https://shogidb2.com/newrecords/page/2
https://shogidb2.com/newrecords/page/3
http://webscraper.io/documentation#scraping-a-site
上のチュートリアルで解説されています。[001-003]で複数連番ページを取得できます。
今回は下の図のようにしました。やりたいことは新着の棋譜(newrecords)とfloodgateの棋譜の、直近の3ページからの「タイトルとリンクの抽出」です。
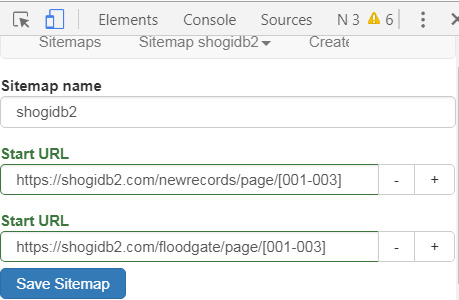
実はStart URLは複数登録できます。フォームの右の+をクリックする事で複数のURLを登録できます。入力が終わったらSave Sitemapをクリック。Selectorの設定は変えないでSitemap shogidb2→Scrapeでスクレイピングしてみます。しばらく待って抽出終わったらSitemap shogidb2→Export data as CSVでCSV形式でダウンロードします。

下の図はダウンロードされたファイルをテキストエディタの秀丸で開いたところです。順番がバラバラで気になるので整形していきます。

以下は秀丸の操作
全選択して編集メニューから変換→ソート
そして以下の図の設定にします。
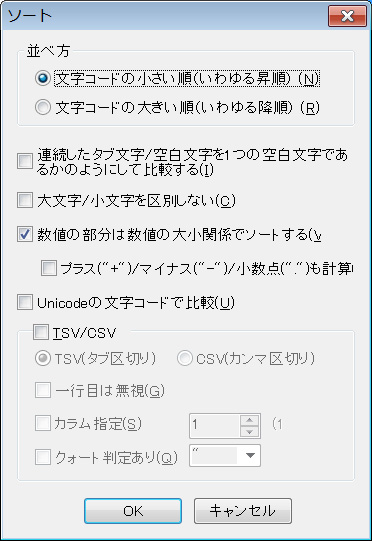
すると以下のように連番で並びます。
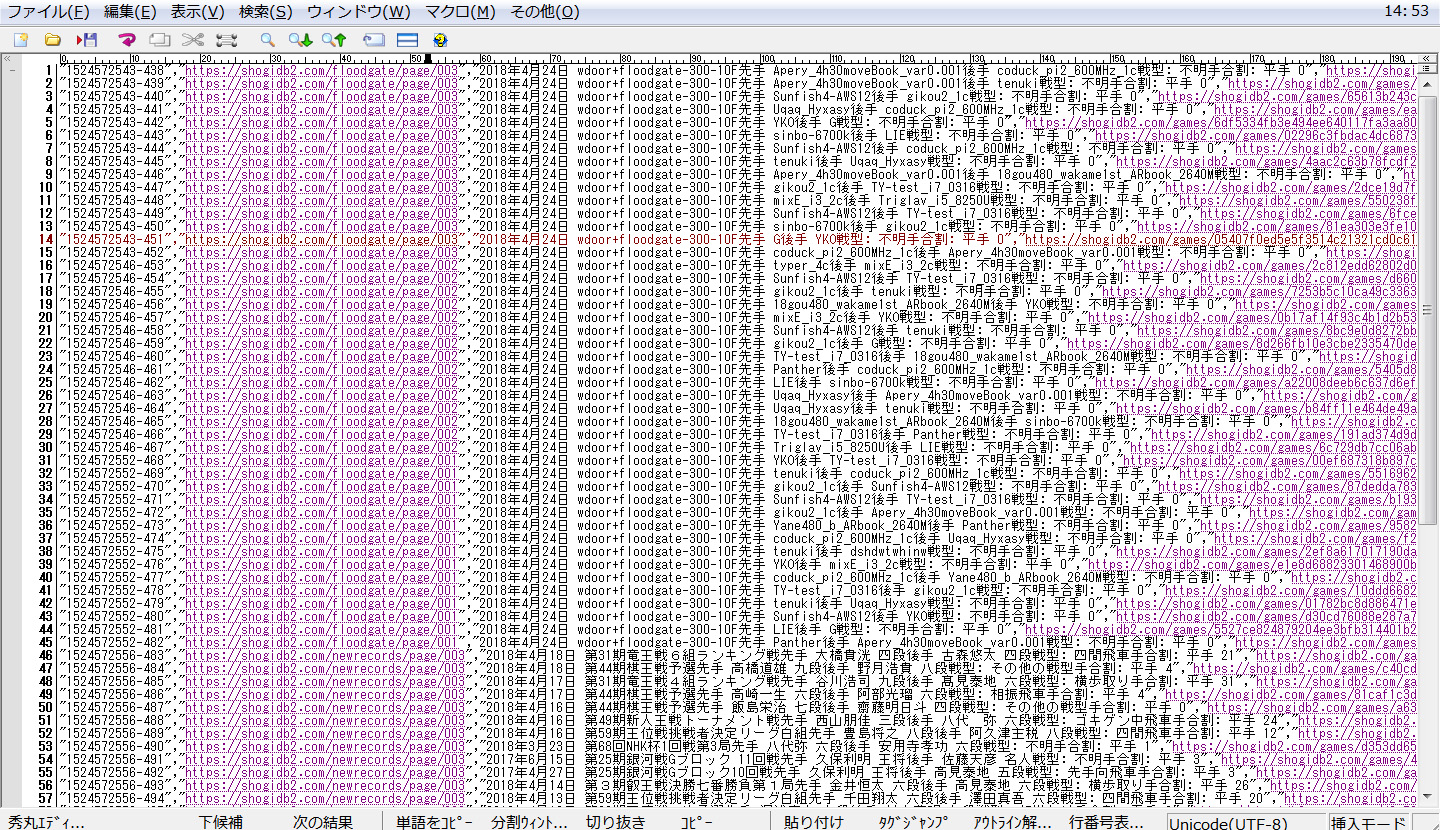
ページネーションは3→2→1と古い順に並び各リンクは下から上に抽出されてます。ちょっと気持ち悪いですが順番は関係ないので良しとします。正しいデータが取得されているかの確認のために並び替えました。ここまででWeb Scraperでの作業は終わりです。ちなみに秀丸ならAlt+選択で以下のように矩形選択してDelキーで不要な箇所を削除したりできます。

リンクをクリックすれば各棋譜ページに飛びユーザーのコメントも見られます。
次回はこのページから「棋譜の書き出し」を使って棋譜形式を指定して保存するまでの作業を自動化させてみたいと思います。

eiju